A single price file update takes 6 hours of manual work, but the labor is the smaller expense. Validation gaps let 8-12% of prices go live with errors. One underpriced high-volume SKU can cost more than a pricing analyst's monthly salary.
One mid-size electrical distributor tracked their manufacturer price file volume for a year. They processed 127 updates, each taking 4-8 hours of analyst time. Annual labor cost: $63,000. Then they audited their live ecommerce prices against the most recent supplier files. Eight percent were wrong. That margin leakage cost $340,000.
Most distributors blame the ERP or the storefront when customers see wrong prices. The failures happen upstream, in the 6-8 hours between receiving the Excel file and clicking import. A single Schneider price update with 14,000 rows has six places where things go wrong.
What a price file update actually involves
Manufacturer email arrives Tuesday morning. Subject line: "Schneider Electric Price Update Effective 4/1." Attached: SCHNEIDER_PRICING_APR2024.xlsx, 14,224 rows. Columns: part number, list price, net multiplier, effective date. Four days to process, validate, and deploy before the effective date, against $2.3 million in monthly Schneider revenue.
Typical price file structure
| Part Number | List Price | Net Multiplier | Effective Date |
|---|---|---|---|
| QO120GFI | $47.50 | 0.68 | 4/1/2024 |
| QO230 | $22.80 | 0.72 | 4/1/2024 |
| EDB14020 | $156.30 | 0.65 | 4/1/2024 |
Base prices update, then 1,200 customer-specific multipliers must recalculate.
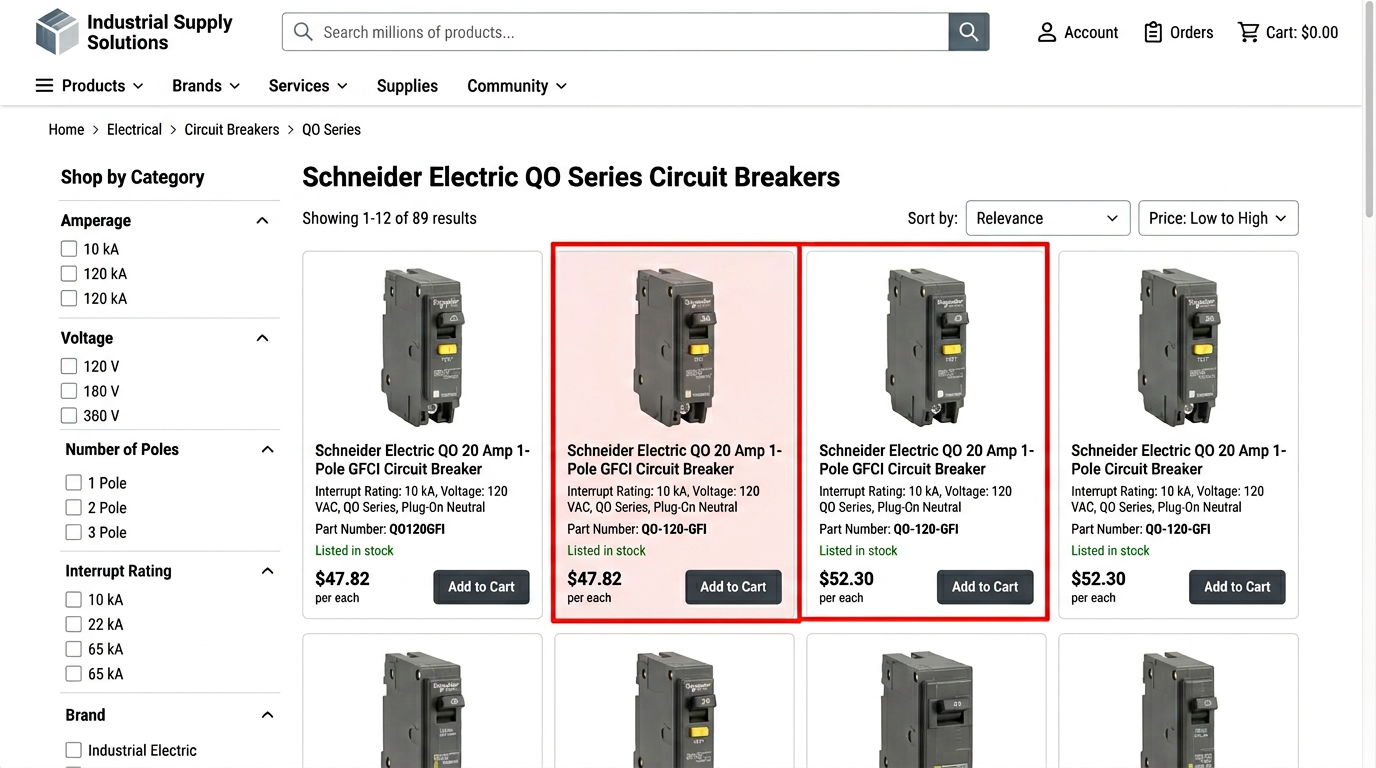
Error point 1: New SKUs not in catalog
Row 8,847: QO2175SB. Not in your master catalog. The import script skips it. Three weeks later, a counter rep quotes the old discontinued part instead. Customer gets the wrong breaker.
Automated validation: Cross-reference every part number against master catalog before import. The pipeline flags unmatched rows automatically and routes them to a review queue. Create new catalog entries first, then rerun the price update. If the supplier file also carries packaging quantities or barcodes, validate those fields in staging too, for example with the unit code validator and the GTIN validator, so a clean price update does not ship broken product metadata alongside it.
Error point 2: Part number format changes
Schneider changed QO120GFI to QO-120-GFI in their system. The import script sees them as different parts. Now you have two catalog entries, one with live pricing, one frozen at last year's cost. The frozen one still appears in search results.
Automated validation: Fuzzy match on manufacturer name plus base part number. The pipeline flags suspected format variants with confidence levels: high-confidence matches merge automatically, medium and low route to a reviewer with both entries shown side by side.
Error point 3: Supplier formula errors
Rows 8,412 through 8,419 show #REF! in the net multiplier column. The supplier's protected Excel template has a broken formula. Your import script reads #REF! as text, fails to parse it, and skips those rows. Seven SKUs now have no pricing at all.
Automated validation: Cell-by-cell error scan before processing. The pipeline rejects any file with #REF!, #VALUE!, or #DIV/0! errors and generates a report showing exactly which rows are affected. No manual scanning required.
New SKU not in catalog: pipeline flags unmatched rows, routes to review queue with suggested catalog entry.
Format variant detected: high-confidence fuzzy matches merge automatically, medium and low route to reviewer.
Formula error in source file: pipeline rejects file, generates error report with affected rows.
Decimal precision mismatch: pipeline preserves full precision per category rules, no truncation.
Retroactive effective date: pipeline flags and generates credit memo list with dollar amounts.
Customer tier dependency: pipeline recalculates all derived prices before publishing.
Error point 4: Decimal truncation
Your import script rounds to 2 decimals. Industrial contactor coils price at 4 decimals: $47.3825. Rounding to $47.38 creates a $0.0025 loss per unit. On a high-volume coil moving 2,000 units per month, that's $5 in margin leakage.
Automated validation: Precision check against product category rules. Electrical components with fractional unit pricing require 4 decimal places. The pipeline detects truncation and preserves full precision automatically.
Error point 5: Retroactive effective dates
The file arrived April 3rd. Rows 2,118 through 2,164 have effective dates of March 15th. You imported on April 4th. Those 47 items needed to be priced retroactively for two weeks. Every order that shipped at the old price now requires a credit memo.
Automated validation: Effective date scan with alert threshold. The pipeline flags any date more than 7 days before file receipt and generates the credit memo list automatically, showing affected orders and dollar amounts.
Error point 6: Customer tier recalculation
Base price on QO120GFI updates from $47.50 to $52.20. Your gold-tier customer has a negotiated 0.85 multiplier. Their price should update from $40.38 to $44.37. But the import script only updates list prices. The customer tier still calculates from the old $47.50 base. Your ecommerce site shows $40.38. You're losing $3.99 per unit.
That customer orders 450 QO120GFI breakers per month. Margin leakage: $1,796 monthly, $21,552 annually, from a single SKU on a single customer account.
Automated validation: Dependency map between base prices and derived prices. When base updates, the pipeline triggers recalculation of all customer-specific tiers before publishing. No manual tier-by-tier recalculation.
Labor cost vs margin leakage
The QO120GFI example costs $2,160 in 30 days. One SKU, one customer. Vistex research puts pricing errors at 8-12% of distributor transactions, eroding 1.8% of gross margin monthly. Most distributors don't have any validation workflow beyond eyeballing a few rows in Excel.
- Automated cross-reference of all part numbers against master catalog
- Fuzzy match pipeline running to detect format variants
- Formula error scan rejecting files with #REF!, #VALUE!, #DIV/0!
- Decimal precision rules enforced per product category
- Retroactive effective dates flagged with credit memo generation
- Customer tier dependencies recalculate automatically on base price change
- Staging import with validation report before production publish
- Automated spot-check comparing 50 random SKUs in live system after publish
Automate the validation, not just the import
One distributor cut their error rate from 8% to under 1% with an automated validation pipeline that runs before anything reaches the ERP. A 14,000-row file processes in under 2 minutes. Clean data passes through. Flagged rows go to a review queue with the specific error and source row attached.
The 6-hour manual window drops to 15 minutes of exception review. And it runs the same way every time. Nobody skips a step because they're rushing on a Friday afternoon. That's the difference between 8% and under 1%.